Project Motivation
When deploying machine learning models in production, choosing the right API protocol can significantly impact performance, scalability, and developer experience. This project aims to provide data-driven insights to help teams make informed decisions.
Goals
- Compare protocol performance (REST vs gRPC vs GraphQL) with HTTP/2
- Measure latency (P50, P95, P99), throughput, and payload sizes
- Provide data-driven recommendations for ML model serving
- Future: Analyze HTTP/1.1 vs HTTP/2 impact per protocol
Current Status: This benchmark compares three popular API protocols (REST, gRPC, and GraphQL) for serving machine learning models, specifically text embeddings using the SentenceTransformer model.
Note: All implementations currently use HTTP/2. HTTP/1.1 comparison is planned for future work.
System Architecture
Executive Summary
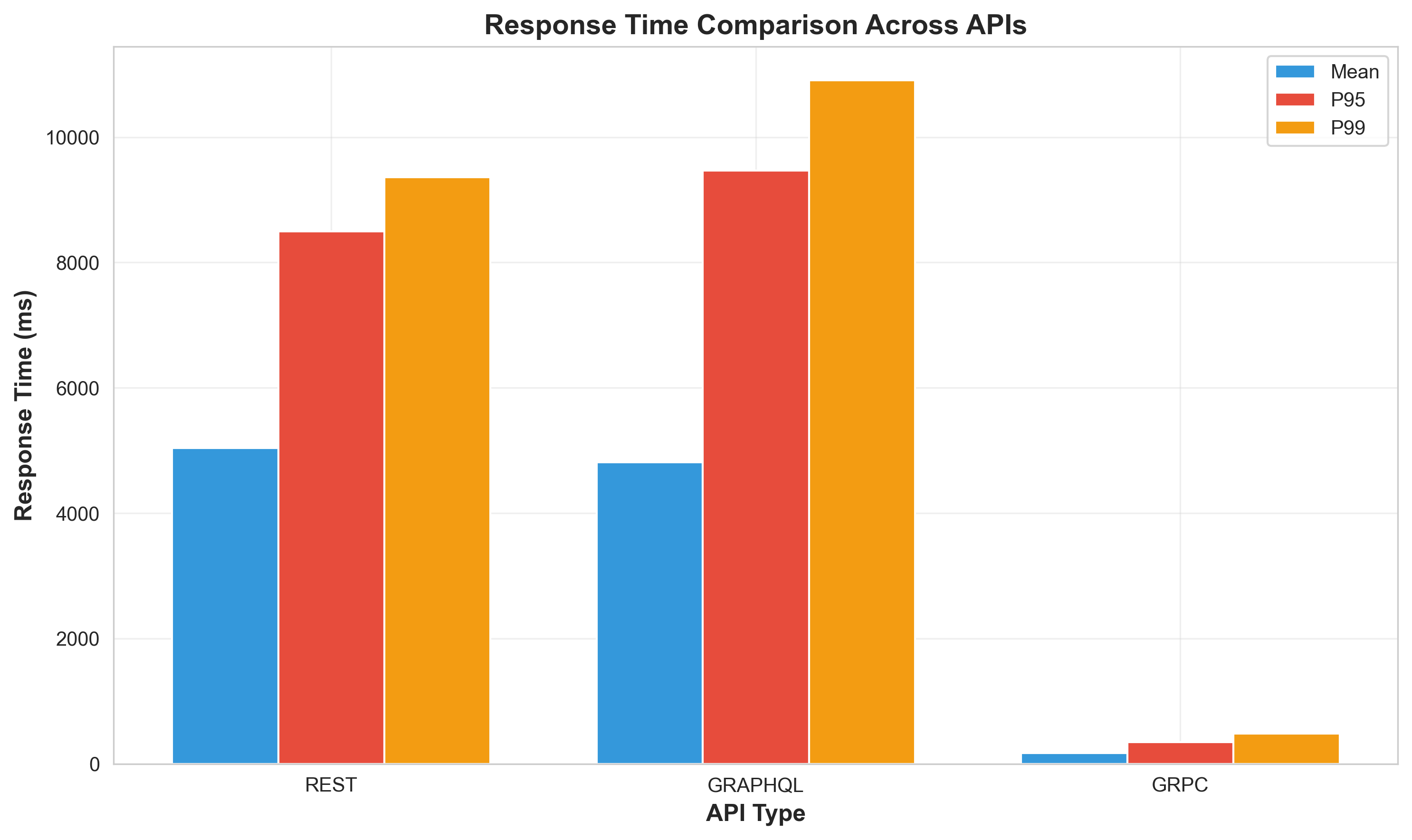
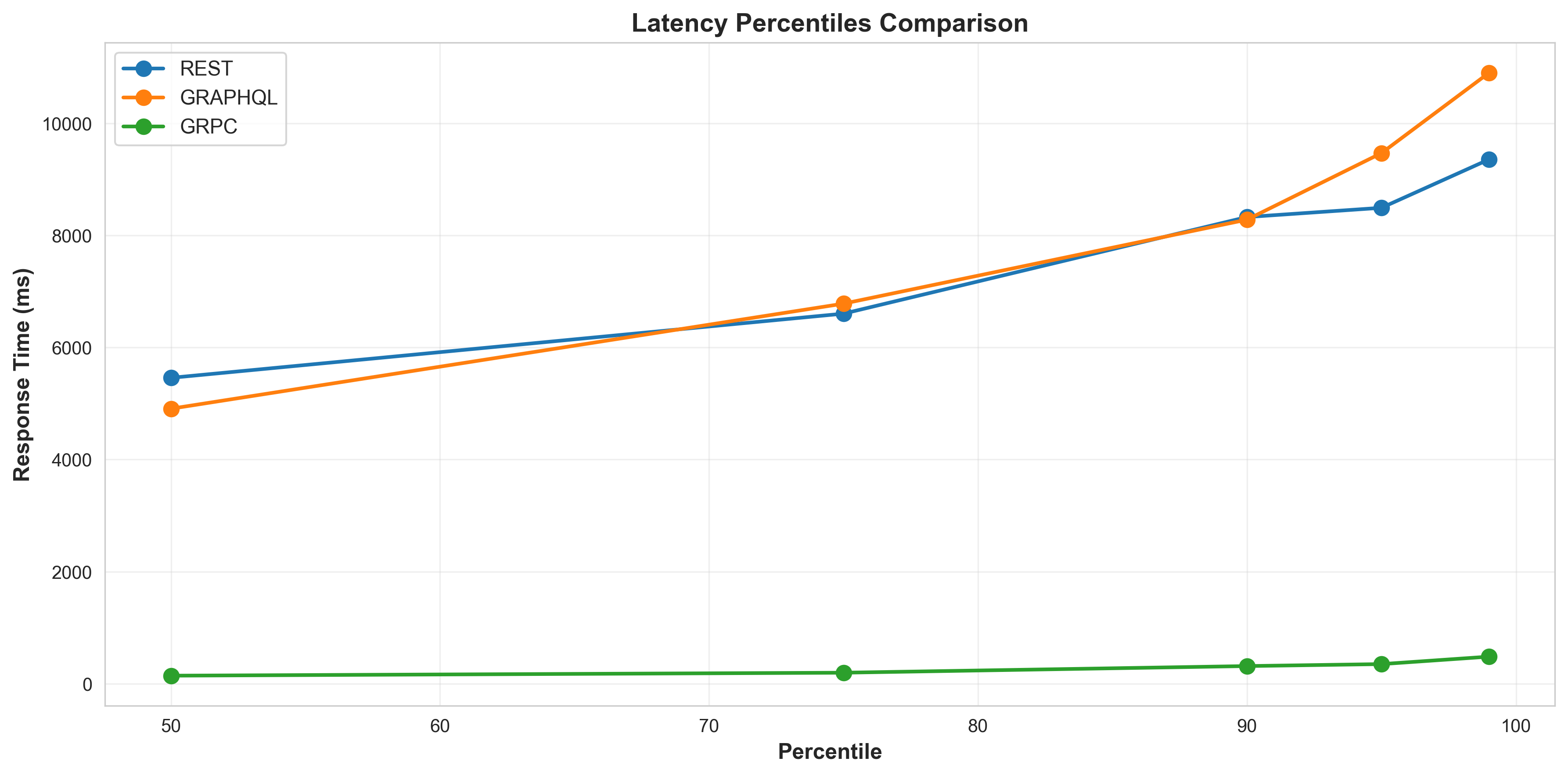
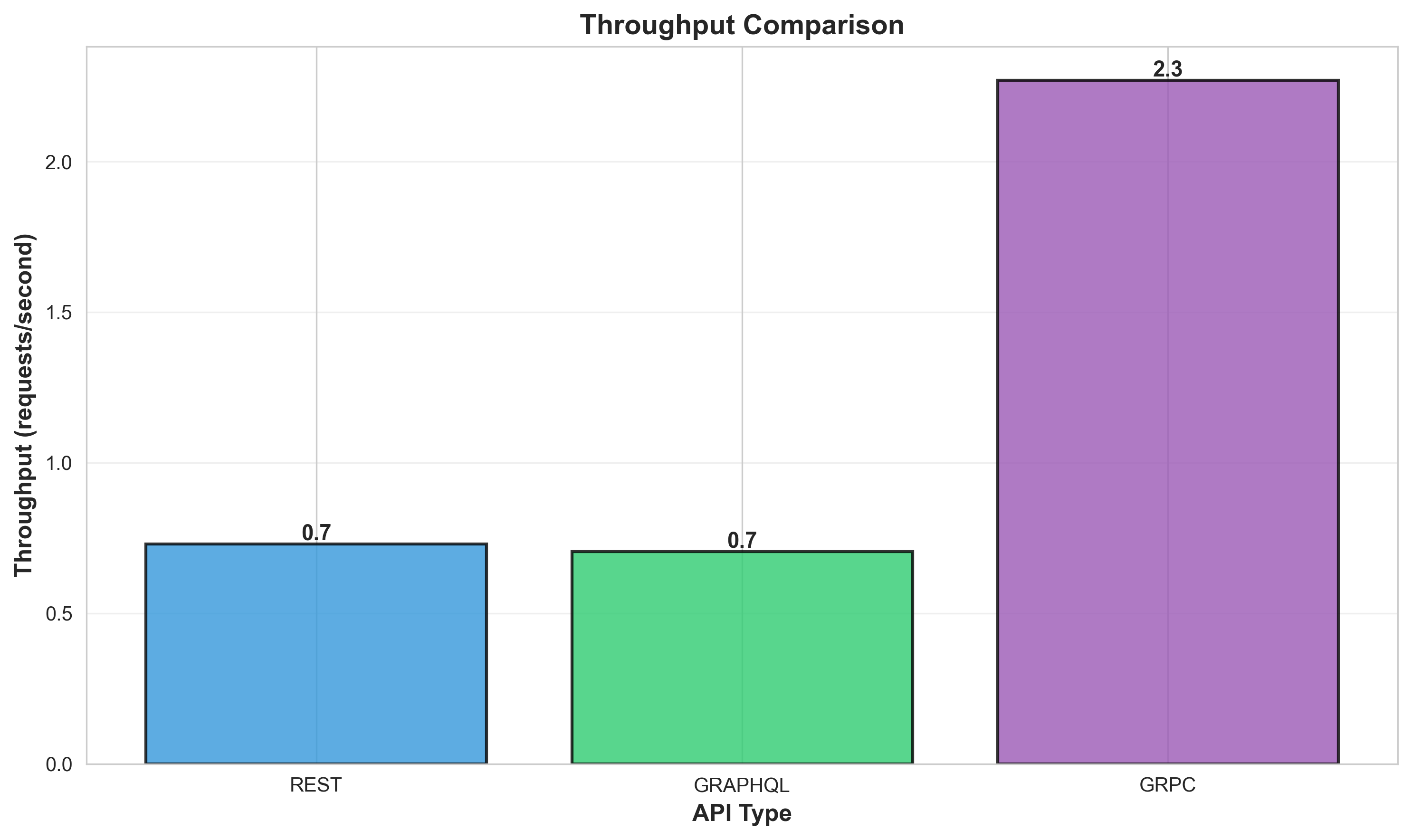
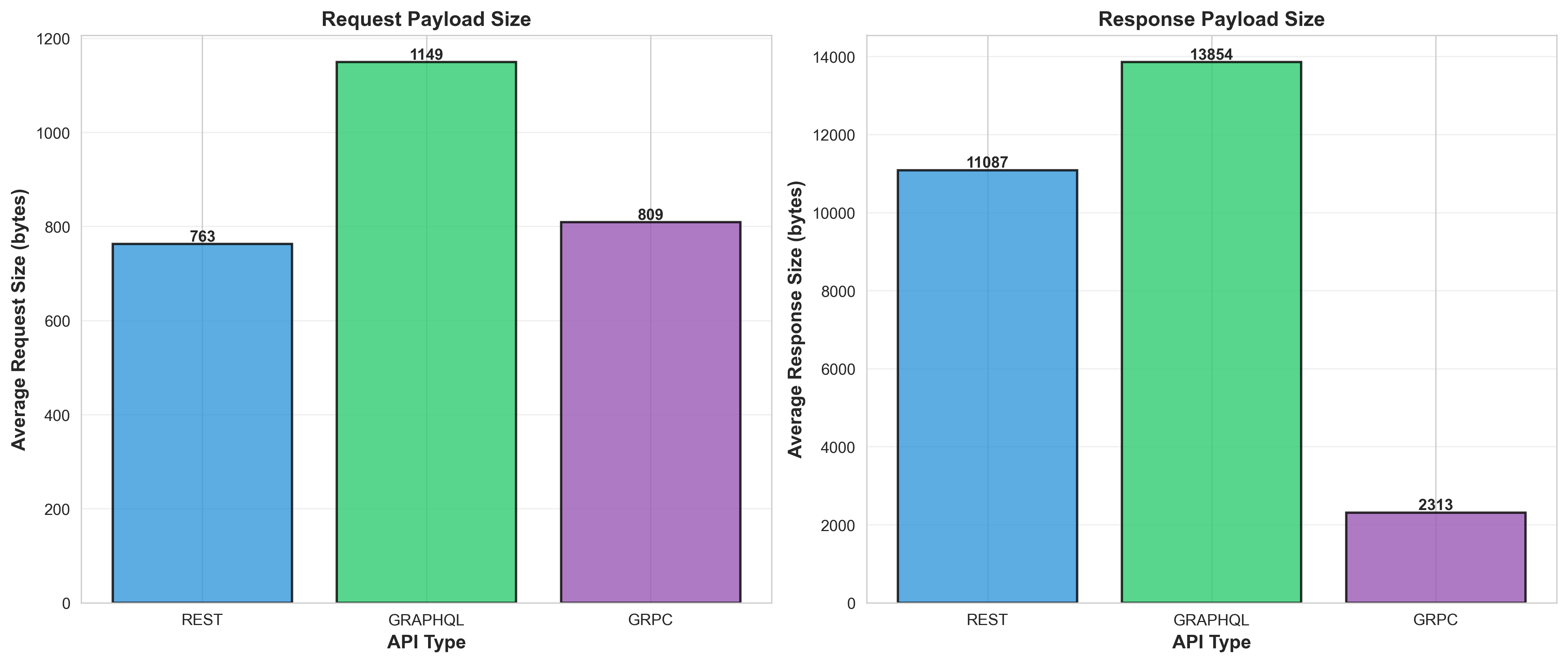
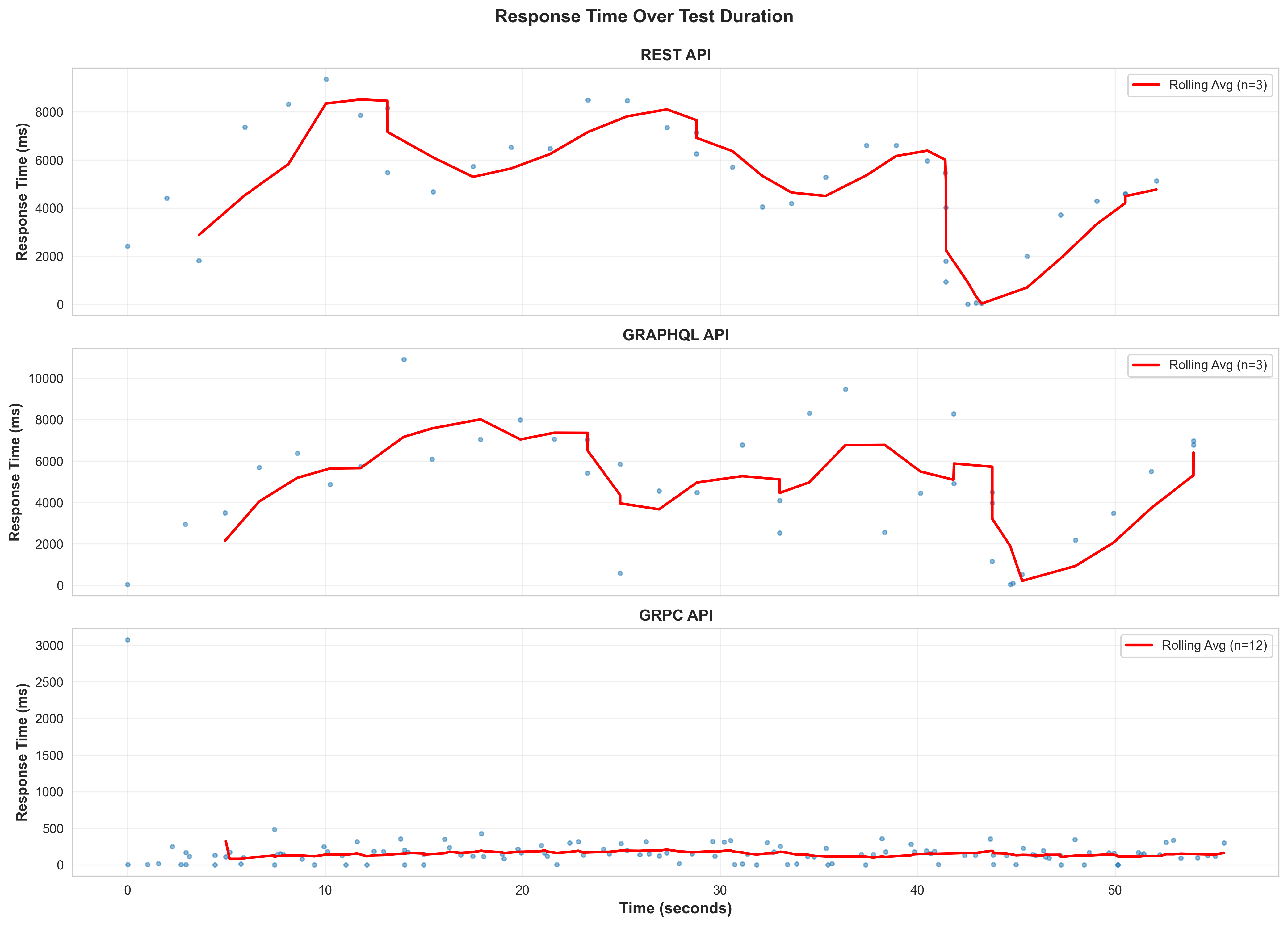
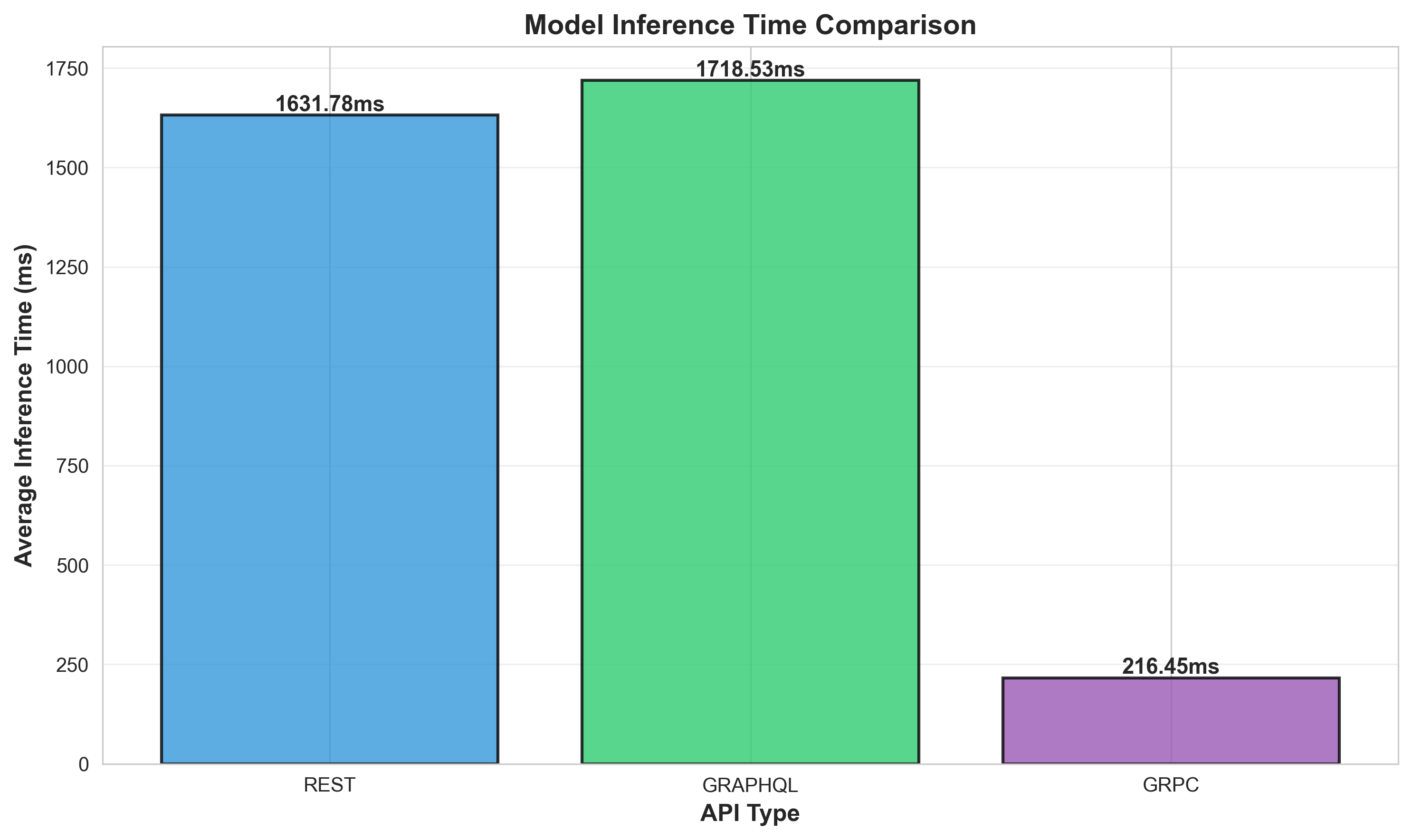
Key Finding: gRPC demonstrates significantly lower latency (~30x faster) and higher throughput (~3x) compared to REST and GraphQL for this ML serving use case.
All implementations use HTTP/2 and the same underlying ML model (SentenceTransformer all-MiniLM-L6-v2) to ensure fair comparison.
Performance at a Glance
REST API
GraphQL API
gRPC API
Detailed Benchmarking Results
Response Time Comparison
Latency Percentiles
Throughput Analysis
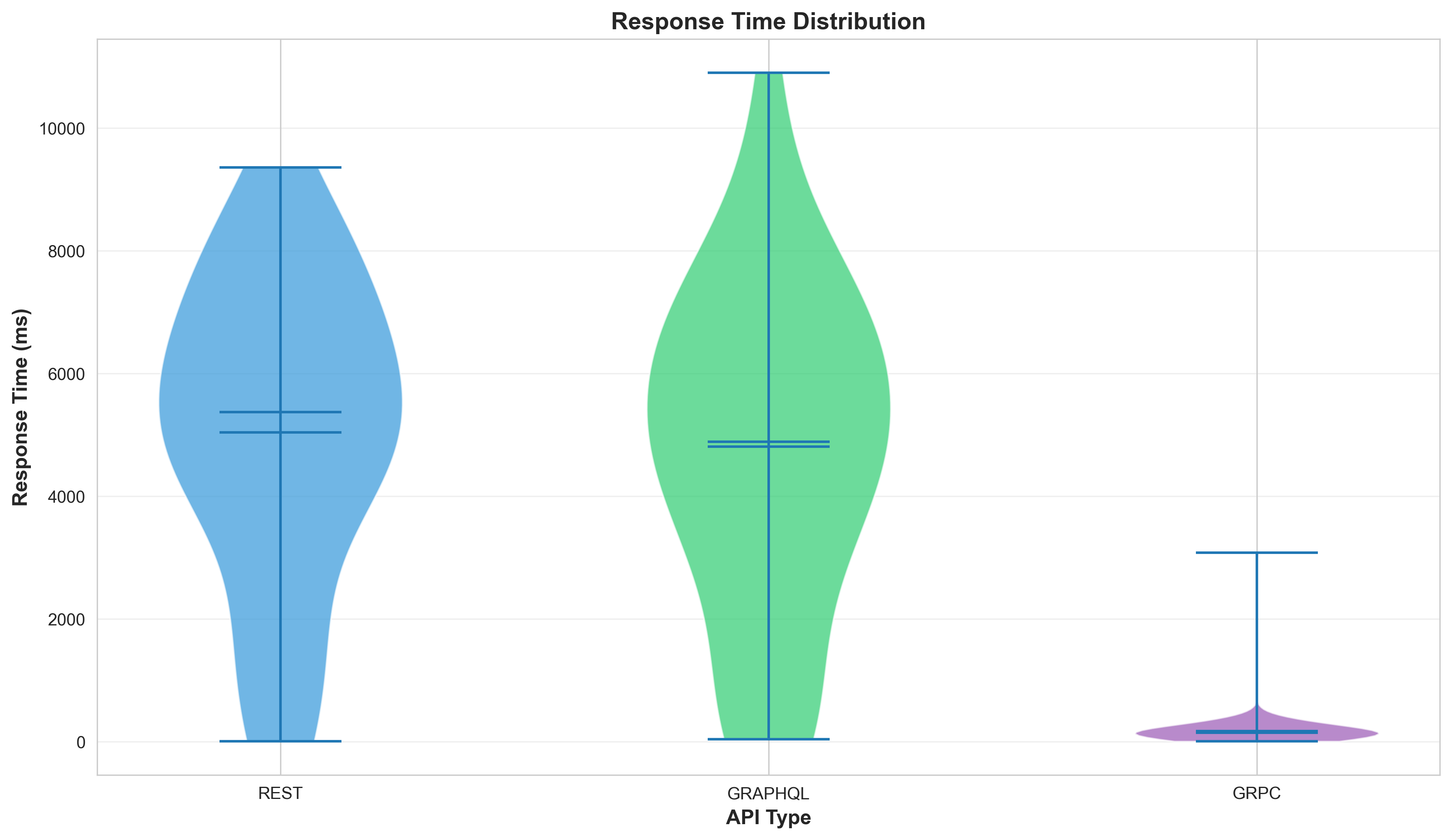
Response Time Distribution
Payload Size Comparison
Response Time Over Test Duration
Success Rate
Model Inference Time
Test Methodology
System Under Test
- Model: SentenceTransformer (all-MiniLM-L6-v2) - 384-dimensional embeddings
- REST API: FastAPI + Hypercorn (HTTP/2)
- GraphQL API: Strawberry GraphQL + Hypercorn (HTTP/2)
- gRPC API: gRPC server (HTTP/2 native with Protocol Buffers)
Test Configuration
- Load Testing Tool: Locust
- Concurrent Users: 10
- Spawn Rate: 2 users/second
- Test Duration: 60 seconds per API
- Test Scenarios: Single embeddings (75%), Batch embeddings (25%)
Workload
- Text lengths: Short (10-50 words), Medium (50-150 words), Long (150-300 words)
- Batch sizes: 5 texts per batch request
- Think time: 1-3 seconds between requests
Environment
- Deployment: Docker containers on the same host
- Monitoring: Prometheus + Grafana
- Network: Local host (minimal network latency)
Analysis and Recommendations
When to Use REST
- Simple, well-understood architecture
- Broad client support and tooling
- Human-readable JSON payloads for debugging
- Best for: Public APIs, microservices with diverse clients
When to Use GraphQL
- Flexible querying - clients specify exactly what data they need
- Single endpoint for multiple operations
- Strong typing and introspection
- Best for: Complex data requirements, mobile apps, BFF (Backend for Frontend) pattern
When to Use gRPC
- High-performance, low-latency requirements
- Binary protocol (Protocol Buffers) reduces payload size
- Built-in streaming support
- Best for: Microservice-to-microservice communication, real-time systems, high-throughput ML inference
Reproduce These Results
Prerequisites
- Docker & Docker Compose
- Python 3.9+
- 8GB RAM minimum
Steps
- Clone the repository:
git clone https://github.com/ranjanarajendran/ml-serving-comparison.git - Start all services:
docker-compose up -d - Run the tests:
./run_tests.sh - View results in
results/charts/